Value iteration – Discounting
In this exercise we will try to implement a value iteration. Value iteration is a method of computing an optimal MDP (Markov decision process) policy and its value. Value iteration starts at the “end” and then works backward, refining an estimate of either optimal policy (model of behavior) or optimal value (and therefore the model of behavior). I just feel obligated to mention, that there is theoretically no end to this problem, but in our case, we will describe the problem with a finite number of state and actions.
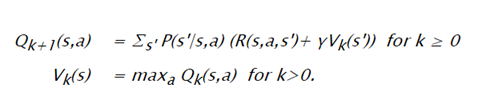
Where

In this exercise we will try to solve the simple pathing problem, of navigating in grid word from a starting point to the “unknown” end. Our goal now wont be to finish at certain location, but to finish with a biggest possible reward.
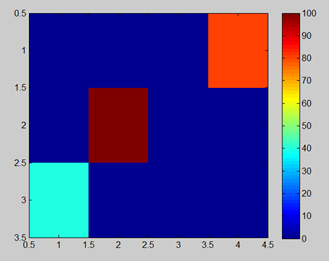
Grid word in Matlab (light blue = start; dark red = wall; orange = goal)
In our task, we can use a simple grid word, where light blue indicates the start point, the “dark red” color at coordination [2,2] is wall. And top right corner with orange color is our reward. Reward is set to 1 (something). This means if our agent reaches the coordination of orange square, he is automatically rewarded with a 1 for example point, and process terminates.
To navigate in the grid word, we will have 4 actions – “N”,”S”,”E”,”W”, representing movement indexed +1 / -1 in certain direction.
To find the optimal behavior for each square, we will use value iteration, and let the agent move to the biggest neighboring value. The algorithm can be expressed as:
- Take the actual grid word state, and copy it to “backup”.
- For each pixel in backup, calculate the new value as a max of all surrounding pixels (N,S,E,W), where each pixel is discounted by a discount factor. For example if ƴ=0.9 and value for N pixel is 8, the actual value for N pixel is 0.9*0.8.
- Set backup (new calculated values) as original grid word for next iteration.
- Repeat until values converge to static values.
Since this can be infinite process, I recommend you to stop after 10 iterations.
| Data | Value |
|---|---|
| Source | https://artint.info/html/ArtInt_227.html |
| Code | Value_iters_code.zip |
| Solution code | Value_iters_solution_code.zip |