Markov decision process
A Markov decision process (MDP) is a discrete time stochastic control process. It provides a mathematical framework for modeling decision making in situations where outcomes are partly random and partly under the control of a decision maker. MDPs are useful for studying optimization problems solved via dynamic programming and reinforcement learning. MDPs were known at least as early as the 1950s, a core body of research on Markov decision processes resulted from Howard’s 1960 book, Dynamic Programming and Markov Processes. They are used in many disciplines, including robotics, automatic control, economics and manufacturing.
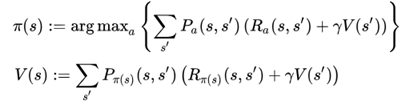
Where V(s) is value function, where we compute the actual value function for an action or square. And Pi(s) represents the behavior model, where we act greedy to the value function. This means that we choose action based on highest value function (based on expected reward in this case).

In our case we will try to solve the problem of previous example, the grid word. However, in this case we will modify the grid, so we can find a new termination state, the fire (yellow). In summation we have a starting point (light blue), wall (dark red), and let’s say golden coin tile (orange) and fire(yellow). In this example we will also introduce different reward for archiving a certain space.
- Gold coin = +10 pts
- Fire = -10 pts
So basically, we reward our agent 10 points for getting into the golden coin, and we penalize him -10 points for stepping into the fire.
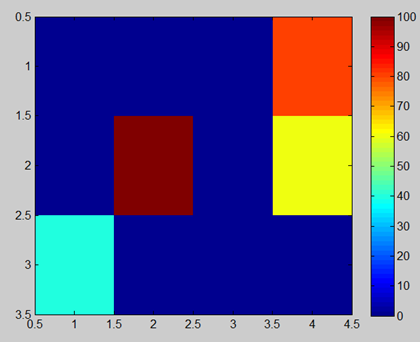
Grid word for MDP (light blue = start; dark red = wall;
orange = +score; yellow = -score)
As a second modification, we introduce a “luck” element. We can also call this the environment element, and just as it is in real life, we can image in as “something went wrong” element of actions. For our purpose of movement in grid word where we have 4 actions available (N,S,E,W), we can imagine this as probability distribution of the landing space.
In our case, we will use simple 80/10/10 % distribution, which means that with a with 80% probability we land on desired square and with 10% probability we either end up on right or left square. This leads to total of 100% so there is no scrapping in movements. Also, I should mention, that going into wall leads to returning to the same location. So in situation where our agent is following top wall of the grid word, and he decides to move west, there is 10% probability to land on the same spot as he was.
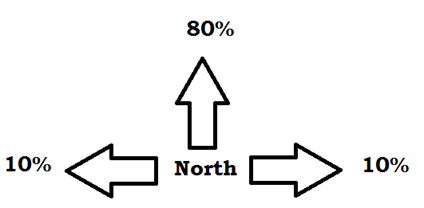
Probability of going north
Algorithm can be done with a equations above.
- Initialize V to zeroes (note: should be 3D array, with size of the grid word * 4 directions)
- For each pixel in grid word calculate the Q value for each action. This can be done by adding together all of landing spaces rewards, with their probabilities of landing. V(s) equation.
- For each pixel decide the optimal behavior, where we act greedy with respect to V(s). Pi(s) equation.
- Repeat until Pi(s) converge
Policy: Dark red = Up; Blue = Down; Green = Right
| Data | Value |
|---|---|
| Source | https://en.wikipedia.org/wiki/Markov_decision_process |
| Code | MDP_code.zip |
| Solution code | MDP_solution_code.zip |